Preparing API data for analytics means converting paginated, nested API responses into a flat, normalized dataset ready for dashboards.
Most teams write scripts for this. They work at first, then break when an endpoint adds a field, changes a type, or returns a slightly different nested object. This guide shows a pipeline approach: combine the responses, transform the JSON, preview the output, and reuse the workflow when the API changes.
Normalize API data for analytics instantly
Clean, flatten, and prepare your JSON for dashboards and warehouses — no code required.
→ Try the API JSON normalization tool for analytics
The problem with raw API data
Raw API responses are rarely analytics-ready. Before you can load them into dashboards, BI tools, spreadsheets, or warehouses, you usually need to fix a few structural problems:
- Pagination splits records across multiple responses
- Nested JSON does not map cleanly to table columns
- Numbers, booleans, and dates may arrive as strings
- Null, empty, or missing fields create inconsistent rows
- Retries or overlapping pages can create duplicate records
The goal is not just to clean one file. The goal is to make API data analytics-ready in a repeatable way, so the same workflow can run again when new responses arrive.
Example: Raw API response
Here’s a typical paginated API response with nested user.email, numeric totals stored as strings, yes/no booleans, a null status, and a duplicate customer across pages.
[
{
"page": 1,
"next": "/customers?page=2",
"data": [
{ "id": "cus_001", "user": { "email": "maya@example.com" }, "total": "29.99", "subscribed": "yes", "status": "active" },
{ "id": "cus_002", "user": { "email": "liam@example.com" }, "total": "49.50", "subscribed": "no", "status": null }
]
},
{
"page": 2,
"next": "/customers?page=3",
"data": [
{ "id": "cus_003", "user": { "email": "ava@example.com" }, "total": "15.00", "subscribed": "yes", "status": "active" },
{ "id": "cus_001", "user": { "email": "maya@example.com" }, "total": "29.99", "subscribed": "yes", "status": "active" }
]
},
{
"page": 3,
"next": null,
"data": [
{ "id": "cus_004", "user": { "email": "noah@example.com" }, "total": "78.25", "subscribed": "no", "status": "active" }
]
}
]How to normalize API JSON for analytics
The pipeline version of this workflow combines smaller JSON operations into one reusable process:
This transforms raw API responses into analytics-ready tables for dashboards, BI tools, and data warehouses.
- Combine paginated responses: collect every page into one array
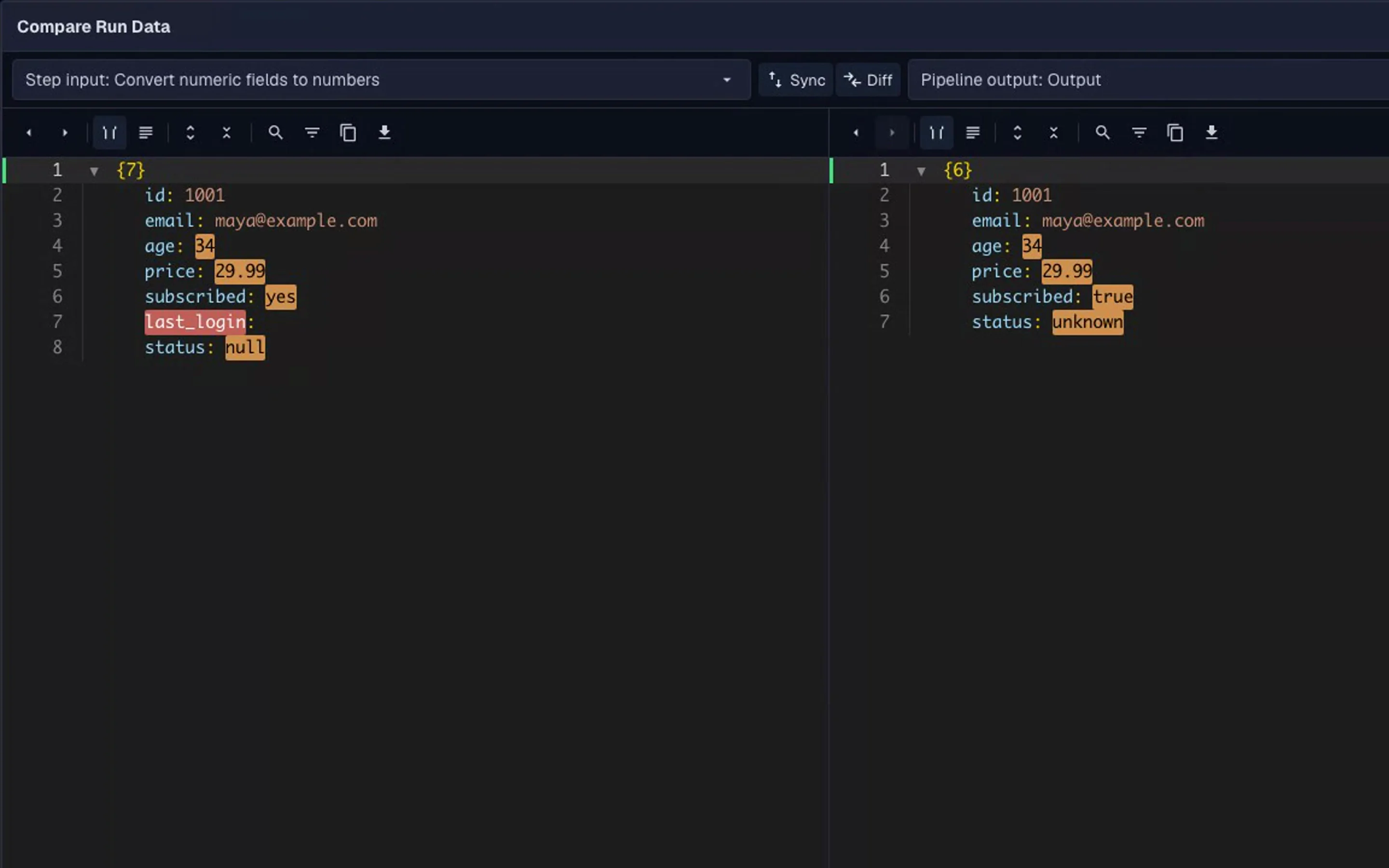
- Flatten nested fields: convert nested objects into top-level keys with
structure.flatten-nest - Normalize values: coerce totals, booleans, dates, and empty values with
convert.format-valuesandconvert.map-values - Clean records: remove nulls and duplicates with
cleanup.clean-json
Step 1 is "get all data" (the pagination article). Steps 2–4 are "make data usable" (this article). The combination delivers what no single utility does alone: an analytics-ready dataset.
How to flatten nested API responses
Flattening JSON is required to convert nested API structures into tabular data for analytics.
For this example, the workflow does:
1. Combine all page results into one array
2. Flatten nested `user.email` into `user_email`
3. Coerce string totals into numbers
4. Map `"yes"`/`"no"` subscribed values into `true`/`false`
5. Remove null fields and duplicate recordsSee how this transformation works step by step in the interactive pipeline below.