Clean API Responses: Remove Nulls, Trim Whitespace, Normalize JSON
Clean API responses by removing nulls, trimming strings, and normalizing JSON for storage, comparison, analytics, and downstream APIs.
2026-02-2512 min readUpdated Apr 30, 2026
Most API responses contain more data than your workflow actually needs.
The same payload might include:
null values that do not carry meaning
empty strings, empty arrays, and optional fields
padded text values like " Alice "
unstable key ordering that creates noisy diffs
This breaks storage, comparison, analytics, exports, and automation workflows. In this guide, you will learn how to clean API responses into smaller, safer JSON using a repeatable cleanup workflow. If fields also change type or meaning, clean first and then normalize inconsistent API fields.
Used in API integrations, ETL workflows, webhook automations, and analytics pipelines, API data cleanup keeps raw JSON usable across systems.
Clean API responses (live tool)
Output(✓)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
{
"users":[
{
"id":1,
"name":" Alice Johnson ",
"email":"alice@example.com",
"phone":null,
"bio":"Software engineer ",
"tags":[],
"address":{
"street":"123 Main St",
"city":"Portland",
"state":"OR",
"zip":"97201",
"apartment":null
},
"preferences":{
"newsletter":true,
"theme":"dark",
"language":"",
"notifications":null
}
},
{
"id":2,
"name":"Bob Smith",
"email":"bob@example.com ",
"phone":null,
"bio":"",
"tags":[
"developer",
"mentor"
],
"address":{
"street":"456 Oak Ave ",
"city":"Seattle",
"state":"WA",
"zip":"98101",
"apartment":""
},
"preferences":{
"newsletter":false,
"theme":" light ",
"language":null,
"notifications":[]
}
}
]
}
Output(✓)
1{
2"users": [
3{
4"address": {
5"city": "Portland",
6"state": "OR",
7"street": "123 Main St",
8"zip": "97201"
9},
10"bio": "Software engineer",
11"email": "alice@example.com",
12"id": 1,
13"name": "Alice Johnson",
14"preferences": {
15"newsletter": true,
16"theme": "dark"
17}
18},
19{
20"address": {
21"city": "Seattle",
22"state": "WA",
23"street": "456 Oak Ave",
24"zip": "98101"
25},
26"email": "bob@example.com",
27"id": 2,
28"name": "Bob Smith",
29"preferences": {
30"newsletter": false,
31"theme": "light"
32},
33"tags": [
34"developer",
35"mentor"
36]
37}
38]
39}
Love the result?
Use this exact pipeline in your app, backend, or LLM workflow.
No setup needed. Works with curl, Node, Python.
Uses example data. For edited input, copy from the playground.
After cleanup, downstream tools no longer need to handle useless phone, empty tags, or padded text every time the response is reused.
What is API response cleaning?
API response cleaning is the process of removing noisy, unused, or inconsistent JSON values so downstream systems can reliably store, compare, transform, and reuse the data.
It is one part of API data cleanup: first remove noise, then normalize JSON data into stable fields, and finally validate or export the cleaned response.
Clean API responses in 3 steps
Remove empty or unused values
Trim and standardize fields
Validate or reuse the cleaned JSON
This ensures a smaller, more predictable API payload for downstream systems.
Why messy API responses are hard to use
Empty values can break downstream assumptions
Padded strings make comparisons unreliable
Optional fields add noise to storage and search
Unstable key order creates noisy diffs
To make API data usable, clean the response before storing, comparing, exporting, or sending it downstream.
Remove empty values such as null, "", and empty arrays
Trim padded strings and normalize key order
Preview the cleaned JSON before exporting it
The goal is not just smaller JSON. The goal is a response that keeps useful data, removes noise, and behaves consistently in storage, analytics, comparison, or automation workflows.
How to clean JSON data from APIs
Cleaning JSON data from APIs means removing values that do not help the next system use the response. That usually includes empty values, whitespace, unused optional fields, and formatting differences that create false changes in diffs.
For API data cleanup, the safest pattern is to remove obvious noise first, then decide whether the remaining fields need normalization, flattening, validation, or export. A JSON cleanup pipeline is the most reliable way to standardize noisy API responses across systems because the same rules can run every time the endpoint returns new data.
The API cleanup workflow
This workflow uses 4 steps:
Remove null values when they do not carry meaning
Remove empty strings, empty arrays, and empty objects
Trim padded strings so text comparisons are stable
Sort keys so repeated API pulls produce cleaner diffs
The combination handles both size reduction and consistency. Each step has a single job, which keeps the cleanup workflow easy to review and reuse.
Clean JSON is the cleanup step in a larger pipeline. Combine it with field normalization, schema validation, or flattening when the cleaned response needs more structure.
These rules usually appear in API pipelines that prepare data for storage, reporting, comparison, queues, or webhook automation. Without a repeatable workflow, cleanup turns into scattered scripts and manual edits that are hard to audit.
For JavaScript background on serializing JSON values, see MDN's guide to JSON.stringify().
API response cleaning examples
Real-world API response cleaning usually starts with where the data is going next:
Webhook payloads: remove empty optional fields before automation rules run.
Customer records: trim padded names, emails, and addresses before deduplication.
Analytics pipelines: remove meaningless null-heavy fields before flattening data for dashboards.
API comparison: sort keys before comparing repeated pulls so diffs show real data changes.
These cases all use the same pattern: define what data is useful, remove values that do not help, then pass the response into a JSON workflow for normalization, validation, export, or comparison.
Example: Raw API response
Before: a user profile API response contains padded strings, null fields, and an empty tags array.
{
"users": [
{
"name": " Alice Johnson ",
"phone": null,
"bio": "Software engineer ",
"tags": []
}
]
}
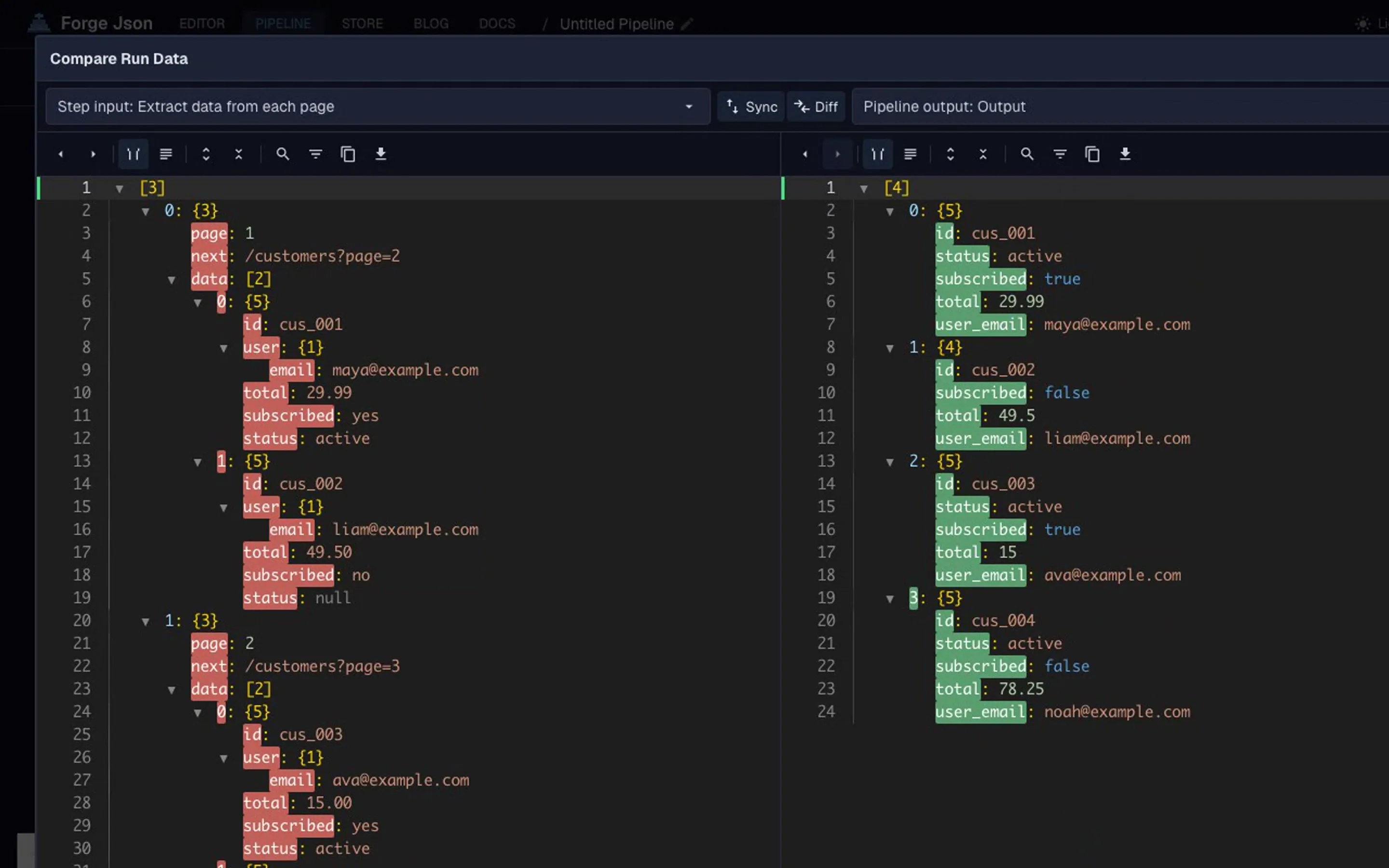
See how this transformation works step by step in the interactive pipeline below.
Use this tool to clean API responses into reusable JSON:
Step-by-step: remove null values from JSON
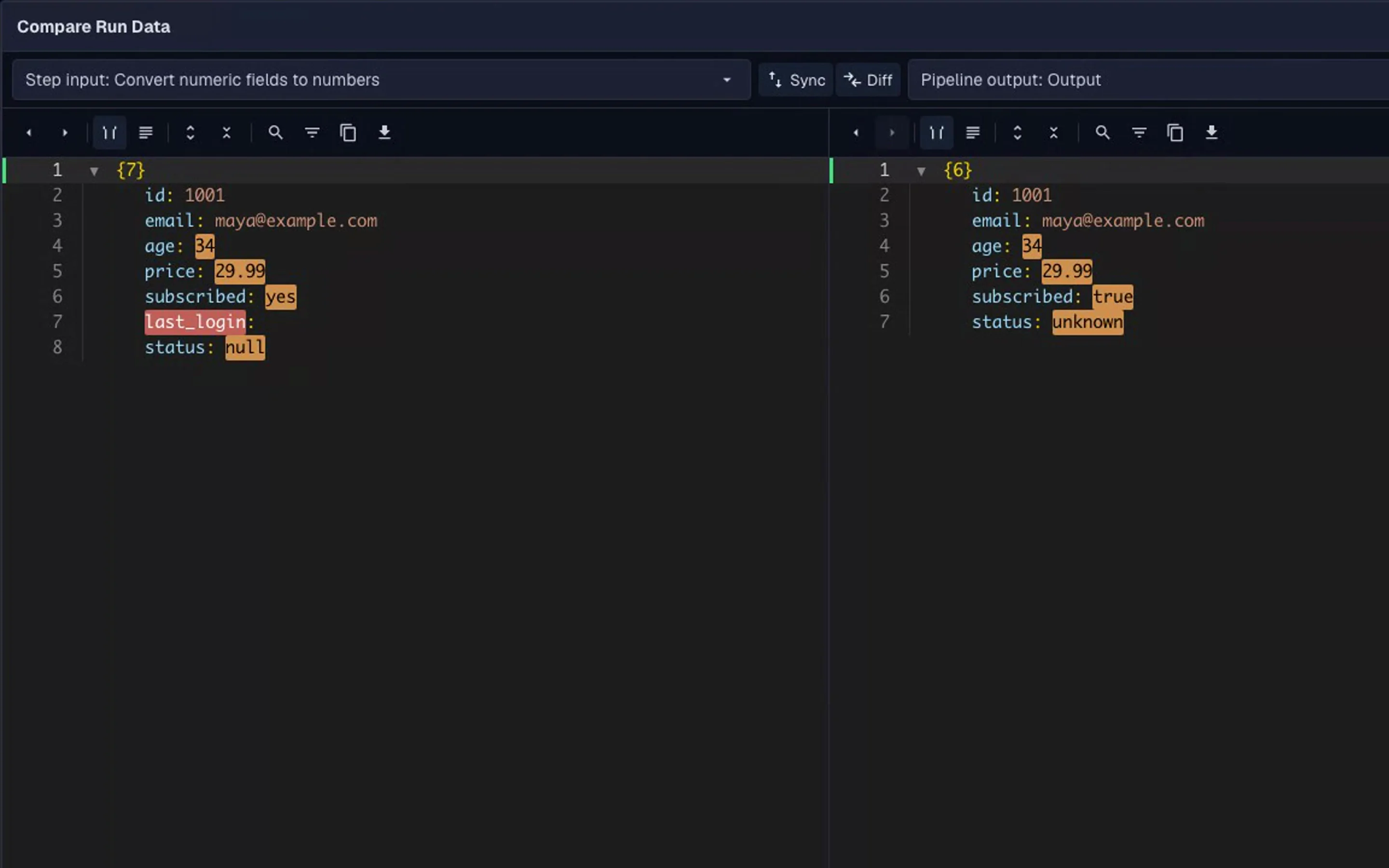
To remove null values from JSON, decide whether null means "unknown", "missing", or "not useful" for your workflow. If null does not carry meaning, remove it before storage, comparison, or export.
The Clean JSON utility can apply the same cleanup rules repeatedly once the method is clear.
Remove empty strings and empty arrays that do not carry useful data.
Trim padded strings and sort keys for stable output.
Result
You end up with:
trimmed strings
fewer empty optional fields
stable key ordering
cleaner JSON for storage, automation, or review
The support material below shows the raw API response, cleanup configuration, and final cleaned output.
How to choose API cleanup rules
Choose cleanup rules based on what the empty or noisy value means downstream:
If null means "unknown", keep it or normalize it later.
If null means "not useful", remove it before storage or export.
If empty strings mean "no value", convert or remove them consistently.
If arrays communicate a meaningful empty list, keep them.
If downstream comparison matters, trim strings and sort keys.
The most important rule is intent. Do not remove every empty value blindly; remove it only when it does not carry meaning for the next system.
API cleanup checklist
Before reusing API JSON downstream, confirm that you have:
Removed meaningless null values
Removed empty strings, arrays, or objects that add noise
Trimmed padded text fields
Kept empty values that carry real business meaning
Sorted keys if future diffs matter
Validated or exported the cleaned structure
Common mistakes when cleaning API responses
The most common mistakes happen when cleanup rules are applied without understanding what the data means:
Removing meaningful null values that represent an intentional state.
Removing empty arrays that downstream systems expect to exist.
Trimming strings after deduplication, which can leave duplicate records unresolved.
Sorting keys but not normalizing field values, which makes the JSON look clean while hidden type issues remain.
Avoid these by defining the target workflow first, cleaning obvious noise second, and then applying the same cleanup rules to every response.
What happens if you don't clean API data?
Messy API data creates hidden operational problems:
Analytics dashboards count empty values as real categories
Storage fills with optional fields nobody uses
API diffs show formatting noise instead of real changes
Automation rules need defensive checks for every field
Cleaning prevents these problems by making the response smaller, more predictable, and easier to inspect before deeper transformation begins.
Clean before normalization
API response cleaning is the first stage before field normalization and schema validation. Once noisy values are removed, downstream rules can focus on meaningful fields instead of padded strings, empty arrays, and unused nulls.
A workflow is better when cleanup rules need to be reused, reviewed, or adjusted:
Non-developers can inspect the cleanup rules
Each cleanup step can be previewed before export
The same workflow can run against future API pulls
Cleanup, normalization, and validation can stay separate
For repeated API cleanup, a reusable workflow is easier to maintain than one-off scripts scattered across imports, reports, and automation jobs.
Why not just clean API data manually?
Manual cleanup works for one file, but it breaks down when API responses keep changing.
Approach
Works for
Breaks when
Manual cleanup
One-off files and quick inspection
The API response changes or the import repeats
Custom script
Stable internal APIs
Non-developers need to review or adjust rules
JSON pipeline
Repeated API cleanup, shared workflows, changing data
Cleanup rules are not defined
Manual API data cleanup also hides transformation rules in spreadsheets, scripts, or ad hoc edits. A pipeline approach is repeatable, auditable, and scalable because the rules stay visible and can run again whenever a new response arrives.
JSON workflow pipeline
Use API response cleaning as the first step in an end-to-end JSON workflow:
Clean API responses with this guide to remove noise, whitespace, null-heavy fields, and values you do not need.
Compare JSON changes across future API pulls when you need to catch response drift over time.
Limitations
API response cleaning can break down when empty values are meaningful or when the payload structure changes.
Common limitations include:
some null values may represent intentional states
empty arrays may still be meaningful for downstream systems
deeply nested fields may need path-specific rules
large API exports may require streaming or chunked processing
For very large JSON files, consider streaming or chunked processing before running the full cleanup workflow.
For these cases, scope cleanup to specific fields, validate the schema, or split cleanup into smaller steps.
If your API data changes often, cleanup is not optional.
Without it, storage fills with noise, analytics drift, and workflows fail silently.
Start with a reusable cleanup workflow and apply it to every API response.
Use the example panel below to open this sample input and run the Clean JSON workflow directly in the editor.
FAQ
How do I clean API responses?
Clean API responses by removing unused empty values, trimming strings, normalizing fields, and keeping only the data your workflow needs.
How do I remove null values from JSON?
You can remove null values by filtering fields programmatically or using a JSON cleanup workflow that removes null fields automatically.
What is JSON normalization?
JSON normalization means transforming data into a consistent structure by removing noise, standardizing fields, and formatting values predictably.
Should I clean API responses with scripts or tools?
Use scripts for stable payloads with simple rules. Use tools or reusable workflows when API responses are nested, inconsistent, or shared across teams.
Support material
Practical example and product context
Use these examples to understand the transformation and apply the same workflow in your own JSON tasks.
Before & After
Example Transformation
See how this workflow reshapes the sample material into clean output.
Input / OutputInputOutput
Input
{
"users": [
{
"id": 1,
"name": " Alice Johnson ",
"email": "alice@example.com",
"phone": null,
"bio": "Software engineer ",
"tags": [],
"address": {
"street": "123 Main St",
"city": "Portland",
"state": "OR",
"zip": "97201",
"apartment": null
},
"preferences": {
"newsletter": true,
"theme": "dark",
"language": "",
"notifications": null
}
},
{
"id": 2,
"name": "Bob Smith",
"email": "bob@example.com ",
"phone": null,
"bio": "",
"tags": [
"developer",
"mentor"
],
"address": {
"street": "456 Oak Ave ",
"city": "Seattle",
"state": "WA",
"zip": "98101",
"apartment": ""
},
"preferences": {
"newsletter": false,
"theme": " light ",
"language": null,
"notifications": []
}
}
]
}
Output
{
"users": [
{
"address": {
"city": "Portland",
"state": "OR",
"street": "123 Main St",
"zip": "97201"
},
"bio": "Software engineer",
"email": "alice@example.com",
"id": 1,
"name": "Alice Johnson",
"preferences": {
"newsletter": true,
"theme": "dark"
}
},
{
"address": {
"city": "Seattle",
"state": "WA",
"street": "456 Oak Ave",
"zip": "98101"
},
"email": "bob@example.com",
"id": 2,
"name": "Bob Smith",
"preferences": {
"newsletter": false,
"theme": "light"
},
"tags": [
"developer",
"mentor"
]
}
]
}
Config
1{
2"removeNulls": true,
3"removeEmptyStrings": true,
4"removeEmptyArrays": true,
5"trimStrings": true,
6"sortKeys": true
7}
Built with Cleanup utility
Open the sample input and generated pipeline in the editor.